Hans Mikelson
Introduction
The talk-box made its popular debut in the song "Rocky Mountain Way" by Joe Walsh. This unique "talking guitar" sound immediately established its niche in audio signal processing. In this article I describe how a talk-box works and how to simulate one using Csound.
How to build a talk-box
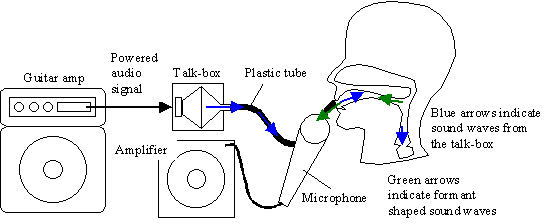
A talk-box is made by completely enclosing a speaker except for a small opening to which a plastic tube is attached. The sound is typically produced by an electric guitar which is then amplified by an overdriven tube amplifier which increases the harmonic content of the signal. The guitar amplifier must be able to supply a powered signal to the talk-box. The talk-box typically uses a horn speaker to direct the sound into the tube. The tube transmits the sound from the enclosure to the musician's mouth. The sound is modified by the musician's vocal tract and then passes into a microphone. The microphone signal is then amplified by a second amplifier to achieve the final result.
Figure 1 A typical talk-box configuration
Simulating the talk-box
The talk-box can be simulated with formant filtering. The shape of the vocal tract adds specific resonances to glottal pulses which transforms the pulses into different vowel sounds. These resonances can be simulated by a series of band pass filters at specific frequencies and amplitudes. Some typical formant frequencies are listed in the following table:
| Vowel | "ee" | "i" | "e" | "ae" | "ah" | "aw" | "u^" | "oo" | "u" | "er" |
| Male spoken |
270 2290 3010 |
390 1990 2550 |
530 1840 2480 |
660 1720 2410 |
730 1090 2440 |
570 840 2410 |
440 1020 2240 |
300 870 2240 |
640 1190 2390 |
490 1350 1690 |
| Male sung |
300 1950 2750 |
375 1810 2500 |
530 1500 2500 |
620 1490 2250 |
700 1200 2600 |
610 1000 2600 |
400 720 2500 |
350 640 2550 |
500 1200 2675 |
400 1150 2500 |
| Female spoken |
310 2790 3310 |
430 2480 3070 |
610 2330 2990 |
860 2050 2850 |
850 1220 2810 |
590 920 2710 |
470 1160 2680 |
370 950 2670 |
760 1400 2780 |
500 1640 1960 |
| Female sung |
400 2250 3300 |
475 2100 3450 |
550 1750 3250 |
600 1650 3000 |
700 1300 3250 |
625 1240 3250 |
425 900 3375 |
400 800 3250 |
550 1300 3250 |
450 1350 3050 |
| Child spoken |
370 3200 3730 |
530 2730 3600 |
690 2610 3570 |
1010 2320 3320 |
1030 1370 3170 |
680 1060 3180 |
560 1410 3310 |
430 1170 3260 |
850 1590 3360 |
560 1820 2160 |
| Amplitudes (db) |
-4 -24 -28 |
-3 -23 -27 |
-2 -17 -24 |
-1 -12 -22 |
-1 -5 -28 |
0 -7 -34 |
-1 -12 -34 |
-3 -19 -43 |
-1 -10 -27 |
-5 -15 -20 |
The talk-box is simulated by passing the audio signal through three band-pass filters with frequencies centered on the formant frequencies. The filtered signals are then scaled according to the amplitudes in the table and added together before the resultant sound is generated. To produce a more significant response from the formants the harmonic content of the signal is increased. In the case of the original talk-box this is done with the guitar amplifier. In the simulated talk-box I use hyperbolic tangent waveshaping. To implement a formant filter in Csound I used three butterbp filters on the distorted signal. The three filtered signals are then scaled by the formant amplitudes and added together before output.
aform1 butterbp adist, kfrm1p, kfrm1p/ibw ; Compute the three resonances aform2 butterbp adist, kfrm2p, kfrm2p/ibw aform3 butterbp adist, kfrm3p, kfrm3p/ibw aout = (aform1*kamp1p+aform2*kamp2p+aform3*kamp3p)/5 ; Scale and sum outs aout*kdeclick, aout*kdeclick ; Write to the output channel
Each vowel is referenced by a number from 0 to 9. These numbers are stored in a table to make it easy to generate different vowel sweeps. The following table defines an "ahhhoooh" vowel sweep:
f30 0 8 -2 4 4 4 4 7 7 7 7
This index is then used to reference tables for each of the formants and for the amplitude. The port opcode is used to create a smoothe sweep from one vowel to the next. This is implmented in the following Csound code where each formant frequency and amplitude is obtained and then swept using port.
kformi oscil 1, 1/idur, ixtab ; Read the formant index table kform1 table kformi, ifmtab1 ; Read the first formant frequency kdb1 table kformi, iatab1 ; Read the first formant dB's kamp1 = dbamp(60+kdb1) ; Convert from decibels to amplitude kform2 table kformi, ifmtab2 ; Read the second formant frequency kdb2 table kformi, iatab2 ; Read the second formant dB's kamp2 = dbamp(60+kdb2) ; Convert dB to amp kform3 table kformi, ifmtab3 ; Read the third formant frequency kdb3 table kformi, iatab3 ; Read the third formnat dB's kamp3 = dbamp(60+kdb3) ; Convert dB to amp kfrm1p port kform1, iptime, 300 ; Portamento to the next formant kamp1p port kamp1, iptime, .15 ; Portamento to the next amplitude kfrm2p port kform2, iptime, 2000 ; Repeat for second kamp2p port kamp2, iptime, .15 kfrm3p port kform3, iptime, 4000 ; and again for the third kamp3p port kamp3, iptime, .15
Conclusion
One of the major problems of the original talk-box is that having the tube in your mouth for an extended performance is very uncomfortable. Another problem is the complex set up required for a talk-box. Formant filtering can come close to creating the vintage talk-box effect without the hassle.
References
Rossing, Thomas D. 1982. The Science of Sound. Addison-Wesley Publishing Company. pp. 290, 320.
Links
An excellent table of formants may be found in the PDF Csound manual available from http://www.lakewoodsound.com/csound/
Suggested Listening
Walsh, Joe. 1972. "Rocky Mountain Way." The Smoker You Drink the Player You Get.MCA.
Frampton, Peter. 1976. "Do You Feel Like We Do" Frampton Comes Alive.A&M.